

Los subtítulos cerrados son una técnica eficaz para mejorar la accesibilidad, la participación y la retención de información durante presentaciones y eventos en vivo. Esto, junto con los cambios en los hábitos de consumo de video en el ámbito de la transmisión de video, ha acelerado recientemente la adopción de subtitulación impulsada por IA en eventos en vivo y reuniones de negocios.
Pero cuando se trata de elegir un proveedor para su propia reunión o evento, la pregunta que se hace con mayor frecuencia es: ¿qué tan precisas son las subtitulaciones automáticas en vivo?
La respuesta rápida es que, bajo condiciones ideales, los subtítulos automáticos en idiomas hablados pueden alcanzar hasta un 98 % de precisión según la Tasa de Error de Palabras (WER).
Y sí, hay una respuesta larga y ligeramente más compleja. En este artículo, queremos ofrecerte una visión general de cómo se mide la precisión, qué factores afectan la precisión y cómo llevar la precisión a nuevos niveles.
En este artículo
- Cómo funciona la subtitulación automática
- ¿Qué se considera una buena calidad de subtitulación?
- ¿Qué factores influyen en la precisión?
- Midiendo la precisión de la subtitulación automática
- Comprender la tasa de error de palabras (WER)
- Obtener subtítulos cerrados increíblemente precisos para tus eventos en vivo
Antes de sumergirnos en los números, demos un paso atrás y veamos cómo funcionan los subtítulos automáticos.
Cómo funciona la subtitulación automática
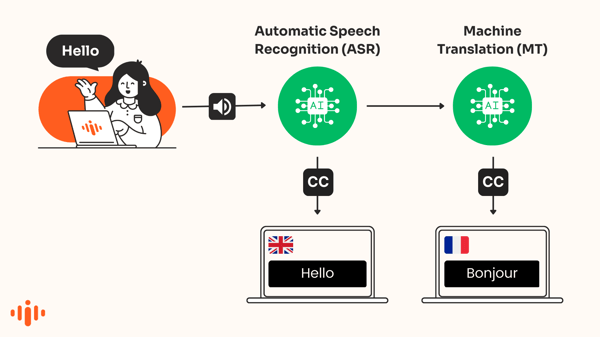
Subtítulos automáticos
Los subtítulos automáticos convierten el habla en texto que se muestra en pantalla en tiempo real en el mismo idioma que el discurso. ASR - Reconocimiento Automático del Habla - es una especie de inteligencia artificial utilizada para producir estas transcripciones de oraciones habladas.
La tecnología, a menudo conocida como "speech-to-text," se utiliza para reconocer automáticamente palabras en audio y transcribir la voz en texto.
Subtítulos traducidos por IA
Los motores de traducción impulsados por IA traducen automáticamente los subtítulos que aparecen en un idioma diferente. Esto también se conoce como subtítulos traducidos por máquina o subtítulos traducidos por máquina.
Artículo recomendado
Por qué deberías considerar añadir subtítulos en vivo a tu próximo evento
En este artículo, estamos cubriendo subtítulos automáticos. Si desea conocer la precisión de los subtítulos traducidos por IA, consulte este artículo.
¿Qué se considera una buena calidad de subtitulación?
La Comisión Federal de Comunicaciones (FCC) estableció características esenciales en 2014 para determinar si los subtítulos son "excelentes":
- Precisión -Los subtítulos deben coincidir con las palabras habladas, en la mayor medida posible
- Completitud - Los subtítulos se extienden desde el principio hasta el final de la transmisión, en la mayor medida posible.
- Ubicación - Los subtítulos no bloquean contenido visual importante y son fáciles de leer.
- Sincronización - Los subtítulos se alinean con la pista de audio y aparecen a una velocidad legible.
Imagen: Subtitulación en vivo traducida por IA durante un seminario web
¿Qué factores influyen en la precisión?
El motor de IA seleccionado
No todos los motores de reconocimiento de voz producen resultados idénticos. Algunos son mejores en general, mientras que otros son mejores en ciertos idiomas. E incluso al usar el mismo motor, los resultados pueden variar mucho dependiendo de los acentos, niveles de ruido, temas, etc.
Por eso, en Interprefy, siempre estamos evaluando los mejores motores para determinar cuál genera los resultados más precisos. Como resultado, Interprefy puede ofrecer a los usuarios la mejor solución para un idioma específico, teniendo en cuenta aspectos como la latencia y el costo. En configuraciones ideales, hemos observado una precisión constante de hasta el 98 % para varios idiomas.
The audio input quality
Se requiere una entrada de calidad para que la tecnología de reconocimiento automático de voz produzca una salida de calidad. Es simple: cuanto mayor sea la calidad y claridad del audio y la voz, mejores serán los resultados.
- Calidad de audio - Al igual que interpretación simultánea, el hardware de entrada de audio deficiente, como los micrófonos integrados en la computadora, puede tener un impacto negativo.
- Discurso claro & pronunciación - Los presentadores que hablan en voz alta, con buen ritmo y claridad, generalmente serán subtitulados con mayor precisión.
- Ruido de fondo - Rugido fuerte, ladridos de perros o el movimiento de papeles que el micrófono capta pueden deteriorar gravemente la calidad del audio de entrada.
- Acentos - Los hablantes con acentos inusuales o fuertes, así como los hablantes no nativos, plantean problemas para muchos sistemas de reconocimiento de voz.
- Superposición de discurso - Si dos personas hablan una encima de la otra, el sistema tendrá mucha dificultad para identificar al hablante correcto.
Artículo recomendado
¿Qué tan precisas son los subtítulos en Zoom, Teams e Interprefy?
Cómo medir la precisión de los subtítulos automáticos
La métrica más común para medir la precisión del ASR es la Tasa de Error de Palabras (WER), que compara la transcripción real del hablante con el resultado de la salida del ASR.
Por ejemplo, si 4 de cada 100 palabras están equivocadas, la precisión sería del 96%.
Comprender la tasa de error de palabras (WER)
WER determines the shortest distance between a transcript text generated by a voice recognition system and a reference transcript that was produced by a human (the ground truth).
WER alinea correctamente las secuencias de palabras identificadas a nivel de palabra antes de calcular el número total de correcciones (sustituciones, eliminaciones e inserciones) necesarias para alinear completamente los textos de referencia y de transcripción. Luego, el WER se calcula como la proporción del número de ajustes necesarios respecto al número total de palabras en el texto de referencia. Un WER más bajo generalmente indica un sistema de reconocimiento de voz más preciso.
Ejemplo de Tasa de Error de Palabras: 91,7% de precisión
Tomemos un ejemplo de una tasa de error de palabras del 8.3% - o una precisión del 91.7% y comparemos las diferencias entre la transcripción original del discurso y los subtítulos creados por ASR:
| Transcripción original: | Salida de subtítulos ASR: |
| Por ejemplo, yo hago me gusta solo un uso muy limitado de los esenciales proporcionados Me gustaría entrar en un punto particular con más detalle, temo que Yo llamo a a los parlamentos estatales individuales para ratificar la convención solo después de que se haya aclarado el papel del tribunal europeo de justicia, lo que podría tener efectos muy perjudiciales. | Por ejemplo, yo también lo haría como solo un uso muy limitado de las exenciones siempre que me gustaría profundizar en un punto particular con más detalle, temo que el llamado a los parlamentos estatales individuales para ratificar la convención solo después de que se haya aclarado el papel del tribunal europeo podría tener efectos muy perjudiciales. |
En este ejemplo, los subtítulos omitieron una palabra y sustituyeron cuatro palabras:
- Medidas: {'matches': 55, 'deletions': 1, 'insertions': 0, 'substitutions': 4}
- Sustituciones: [('too', 'do'), ('use', 'used'), ('exemptions', 'essentials'), ('the', 'i')]
- Eliminaciones: ['would']
El cálculo de la Tasa de Error de Palabras es, por lo tanto:
WER = (eliminaciones + sustituciones + inserciones) / (eliminaciones + sustituciones + coincidencias) = (1 + 4 + 0) / (1 + 4 + 55) = 0.083
WER pasa por alto la naturaleza de los errores
Now in the example above, not all errors are equally impactful.
La medida WER puede ser engañosa porque no nos indica cuán relevante/importante es un determinado error. Los errores simples, como la ortografía alternativa de la misma palabra (movable/moveable), no suelen ser considerados errores por el lector, mientras que una sustitución (exemptions/essentials) podría tener un mayor impacto.
Los números de WER, particularmente para sistemas de reconocimiento de voz de alta precisión, pueden ser engañosos y no siempre corresponden a las percepciones humanas de corrección. Para los humanos, las diferencias en los niveles de precisión entre 90 y 99% a menudo son difíciles de distinguir.
Tasa de error de palabras percibida
Interprefy ha desarrollado una métrica de error de ASR propietaria y específica por idioma llamada WER percibido. Esta métrica solo cuenta los errores que afectan la comprensión humana del discurso y no todos los errores. Los errores percibidos suelen ser más bajos que el WER, a veces incluso hasta un 50%. Un WER percibido del 5-8% suele ser apenas perceptible para el usuario.
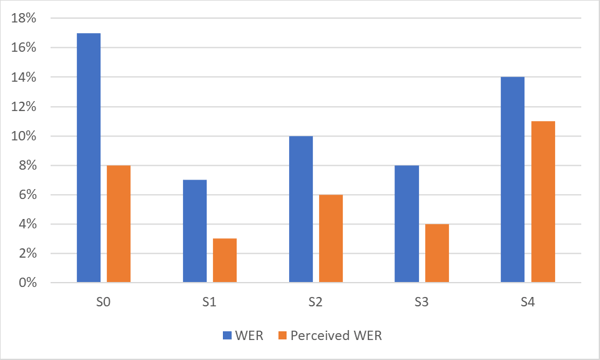
El gráfico a continuación muestra la diferencia entre WER y WER percibido para un sistema ASR altamente preciso. Observe la diferencia en el rendimiento para diferentes conjuntos de datos (S0-S4) del mismo idioma.
Como se muestra en el gráfico, el WER percibido por los humanos suele ser sustancialmente mejor que el WER estadístico.
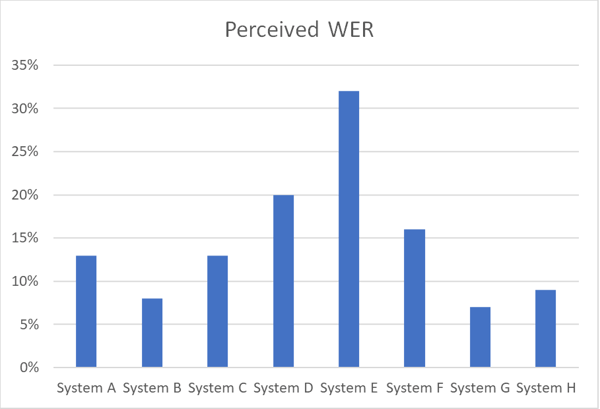
El gráfico a continuación ilustra las diferencias de precisión entre varios sistemas ASR que trabajan con el mismo conjunto de datos de voz en un determinado idioma utilizando WER percibido.
Obtener subtítulos cerrados increíblemente precisos para tus eventos en vivo
Hemos visto una precisión del 97% para nuestras subtitulaciones automáticas gracias a la combinación de nuestra solución técnica única y al cuidado que brindamos a nuestros clientes. Alexander Davydov, Director de IA Delivery en Interprefy
Si'estás buscando tener subtítulos automáticos altamente precisos durante un evento, hay tres cosas clave que deberías considerar:
Utilice una solución de primera clase
En lugar de elegir cualquier motor listo para usar que cubra todos los idiomas, opte por un proveedor que utilice el mejor motor disponible para cada idioma en su evento.
¿Interesado en comprender lo que el mejor motor puede ofrecerle? Lea nuestro artículo: El futuro de los subtítulos en vivo: cómo la IA de Interprefy potencia la accesibilidad
Optimizar el motor
Elija un proveedor que pueda complementar la IA con un diccionario a medida para garantizar que los nombres de marcas, nombres poco comunes y acrónimos se capturen adecuadamente.
Asegure una entrada de audio de alta calidad
Si la entrada de audio es mala, el sistema ASR no podrá lograr una calidad de salida. Asegúrate de que el discurso se capture alto y claramente.


 Más enlaces de descarga
Más enlaces de descarga



